Background Information on HPAs
The Horizontal Pod Autoscaler (HPA) is a Kubernetes feature that allows you to configure your cluster to automatically scale the services it's running up or down. This section provides explanation on how HPA works with Kubernetes.
Why Use Horizontal Pod Autoscaler?
Using HPA, you can automatically scale the number of pods within a replication controller, deployment, or replica set up or down. HPA automatically scales the number of pods that are running for maximum efficiency. Factors that affect the number of pods include:
- A minimum and maximum number of pods allowed to run, as defined by the user.
- Observed CPU/memory use, as reported in resource metrics.
- Custom metrics provided by third-party metrics application like Prometheus, Datadog, etc.
HPA improves your services by:
- Releasing hardware resources that would otherwise be wasted by an excessive number of pods.
- Increase/decrease performance as needed to accomplish service level agreements.
How HPA Works
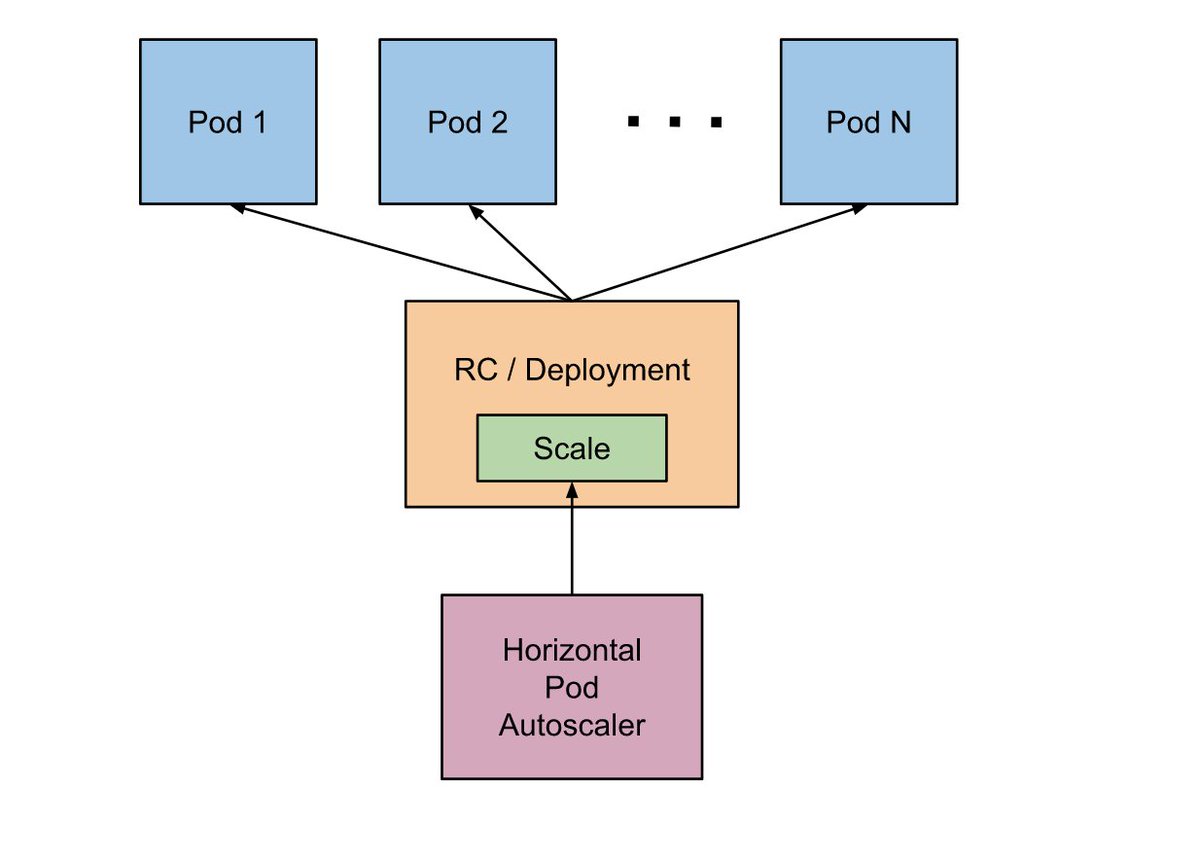
HPA is implemented as a control loop, with a period controlled by the kube-controller-manager flags below:
| Flag | Default | Description |
|---|---|---|
--horizontal-pod-autoscaler-sync-period | 30s | How often HPA audits resource/custom metrics in a deployment. |
--horizontal-pod-autoscaler-downscale-delay | 5m0s | Following completion of a downscale operation, how long HPA must wait before launching another downscale operations. |
--horizontal-pod-autoscaler-upscale-delay | 3m0s | Following completion of an upscale operation, how long HPA must wait before launching another upscale operation. |
For full documentation on HPA, refer to the Kubernetes Documentation.
Horizontal Pod Autoscaler API Objects
HPA is an API resource in the Kubernetes autoscaling API group. The current stable version is autoscaling/v1, which only includes support for CPU autoscaling. To get additional support for scaling based on memory and custom metrics, use the beta version instead: autoscaling/v2beta1.
For more information about the HPA API object, see the HPA GitHub Readme.